
Why Should You Use DynamoDB Streams?
Table of Contents
Introduction to DynamoDB
Amazon DynamoDB is a Serverless, Fully-Managed, Key-Value NoSQL database. It was designed to run high-performance applications at any scale. It offers continuous backups, in-memory caching, automated multi-region replication, built-in security, and data export tools. Amazon DynamoDB also allows you to build Internet-scale applications that can support caches and user-content MetaData that require high concurrency. It also lets you deliver seamless retail experiences. You can do this by leveraging design patterns for deploying workflow engines, shopping carts, customer profiles and inventory tracking.
Amazon DynamoDB is known for supporting high-traffic, extremely scaled events. It also allows you to focus on driving innovation with no operational overhead. Amazon DynamoDB integrates with AWS Lambda to provide triggers. You can use triggers to automatically execute a custom function when item-level changes in a DynamoDB table are detected.
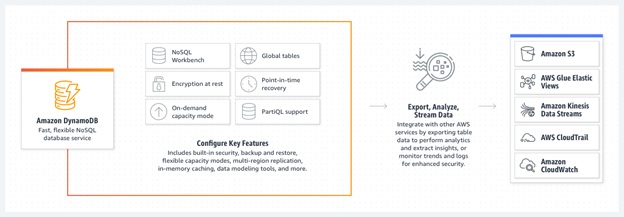
Here are a few useful features of Amazon DynamoDB:
- Auto Scaling: For tables that use provisioned capacity, DynamoDB delivers automatic scaling of storage and throughput based on your previously set capacity by monitoring the performance usage of your application. When your application traffic increases, Amazon DynamoDB increases the throughput to accommodate the load. If your application traffic decreases, Amazon DynamoDB accordingly scales down so that you pay less for unused capacity.
- On-Demand Mode: You can use this mode for both existing and new tables, and you can continue using the existing DynamoDB APIs without changing the code.
- Change Tracking with Triggers: You can use triggers to build applications that react to data modifications in DynamoDB tables. The Lambda functions can perform any actions specified by you. For instance, initiating a workflow or sending a notification.
- Read/Write Capacity Modes: For workloads that are comparatively less predictable, the On-demand Capacity mode can take care of the managing capacity for you and you only have to pay for what you consume.
- Point-in-time Recovery: Point-in-time Recovery (PITR) allows you to protect your Amazon DynamoDB tables from accidental delete or write operations. PITR offers continuous backups of your Amazon DynamoDB table data, and you can restore that table to any point in time up to the second in the previous 35 days. You can easily initiate backup and restore operations or PITR with a single click using a single API call or in the AWS Management Console.
Introduction to DynamoDB Streams
DynamoDB Streams combines with AWS Services to help you solve issues regarding archiving and auditing data, triggering an event based on a particular item change, and replication of data across multiple tables to name a few. When enabled, DynamoDB Streams can capture a time-ordered sequence of item-level modifications in an Amazon DynamoDB table. It can also durably store the information for up to 24 hours. Applications can access a series of stream records, from an Amazon DynamoDB stream in near real-time.
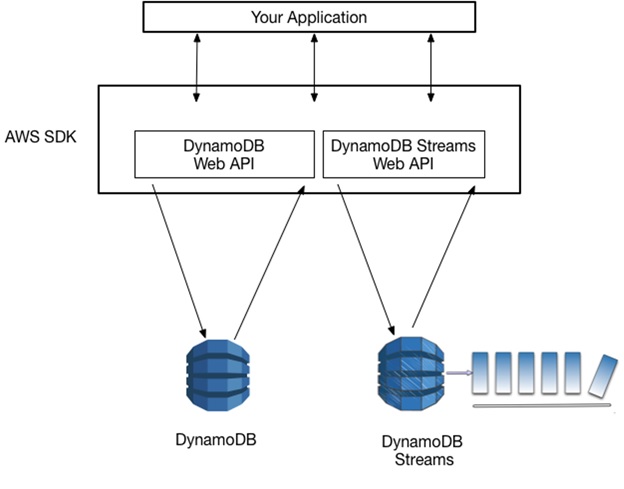
To work with database indexes and tables, your application must access an Amazon DynamoDB endpoint. Here are a few stream record views supported by DynamoDB Streams:
- KEYS_ONLY: This refers to only the key attributes of the modified item.
- OLD_IMAGE: This refers to the entire item as it appeared before it was modified.
- NEW_IMAGE: This refers to the entire item as it appeared after it was modified.
- NEW_AND_OLD_IMAGES: This Stream Record View depicts both the old and new images of the item.
DynamoDB Streams can be processed in various ways. You can either use AWS Lambda or a standalone application that leverages the Kinetic Client Library (KCL) alongside the DynamoDB Streams Kinesis Adapter. KCL is a client-side Library that provides an interface to process DynamoDB Stream changes. It is changed by the DynamoDB Streams Kinesis Adapter to look at the unique record views returned by the DynamoDB Streams service.
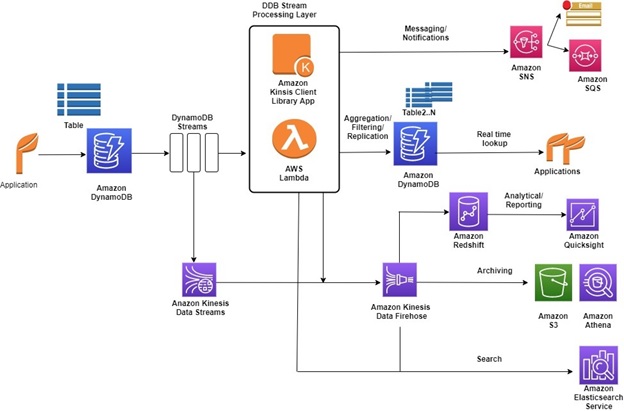
Understanding the Best Practices for Working with DynamoDB Streams
Here are a few best practices for working with DynamoDB Streams:
- You should design your stream-processing layer to handle different types of failures. Ensure that you store the stream data in a dead letter queue such as Amazon S3 or Amazon SQS, for later processing in the event of a failure.
- All item-level changes should be in the stream, including deletes. Your application should be capable of handling creations, deletes, and updates.
- DynamoDB Streams allow you to build solutions using near-real-time synchronization. It doesn’t enforce Transactional capability or Consistency across many tables. This needs to be handled at the application level. You also need to be aware of the Latency involved in the processing of Stream data as it gets propagated in the stream. This allows you to define the SLA regarding data availability for your end-users and downstream applications.
- Consider AWS Lambda for Stream Processing whenever possible because it is serverless and therefore easier to manage. Check to see if Lambda can be used, otherwise, you can use the Kinesis Client Library (KCL).
- Failures can occur in the application that reads the events from the stream. You should design your application to minimize the blast radius and risk. Also, try not to update too many tables with the same code. You can also define your processing to be This allows you to retry safely. It is recommended that you catch different exceptions in your code and decide if you want to ignore or retry the records and put them in a DLQ for further analysis.
- You should be aware of the following constraints while designing consumer applications:
- Maximum two processes should be reading from a stream shard at the same time.
- Data Retention in the streams is only 24 hours.
Conclusion
This article highlights a few key aspects of DynamoDB Streams. This includes its benefits, features, and importance.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate and load data from 100+ sources (including 40+ Free Data Sources) to a destination of your choice in real-time in an effortless manner. Hevo with its minimal learning curve can be set up in just a few minutes allowing the users to load data without having to compromise performance. Its strong integration with umpteenth sources allows users to bring in data of different kinds in a smooth fashion without having to code a single line.
The Best Forex Brokers for Beginners
Since COVID-19 first popped up, interest in the forex market has increased dramatically. Knowing how to get involved with minimal…

{kind=link}
Maximizing Success: The Symbiosis of Dedicated Software Development Teams and Product Design Services
The Symbiosis of Dedicated Software Development Teams and Product Design Services In the rapidly evolving landscape of technology, businesses aiming…